تطبيق خطي
في الرياضيات، التطبيق الخطي linear map (المسمى أيضاً التعيين الخطي، أو التحويل الخطي، أو تشاكل فضاء متجه، أو في بعض السياقات دالة خطية) هي تعيين بين فضائين متجهين للحفاظ على عمليات إضافة المتجهات و الضرب العددي. يتم استخدام نفس الأسماء ونفس التعريف أيضاً للحالة الأكثر عمومية لـ الوحدات على الحلقات؛ انظر تشاكل وحدة.

إذا كان التطبيق الخطي عبارة عن تقابل فإنها تسمى تساوي الشكل. في الحالة التي يكون فيها ، يسمى التطبيق الخطي (خطياً) إندومورفية. أحياناً يشير المصطلح العامل الخطي إلى هذه الحالة،[1] ولكن يمكن أن يكون لمصطلح "العامل الخطي" معانٍ مختلفة لمصطلحات مختلفة: على سبيل المثال، يمكن استخدامه للتأكيد على أن و هما مسافات متجهة حقيقية (ليس بالضرورة مع ),[citation needed] أو يمكن استخدامها للتأكيد على أن هو فضاء دالة، وهو اصطلاح شائع في التحليل الدالي.[2]أحيانًا يكون للمصطلح نظم خطية نفس معنى التطبيق الخطي، بينما في التحليل ليس كذلك.



تطبيق خطي من V إلى W دائماً تعين أصل V إلى أصل W. علاوة على ذلك، فإنه يقوم بتعيين فضاء خطي جزئي في V على فضاءات فرعية خطية في W (ربما ذات بعد أقل);[3]على سبيل المثال، تقوم بتعيين المستوى من خلال الأصل في V إلى إما مستوى من خلال الأصل في W، و خط من خلال الأصل في W، أو مجرد الأصل في W. غالباً ما يمكن تمثيل التطبيق الخطي على أنه مصفوفات، وتشمل الأمثلة البسيطة الدوران والانعكاس في التحويلات الخطية.
في لغة نظرية التصنيفات، التطبيق الخطي هو انحفاظ الشكل في الفضاءات المتجهة.
Definition and first consequences
Let and be vector spaces over the same field . A function is said to be a linear map if for any two vectors and any scalar the following two conditions are satisfied:




- Additivity / operation of addition
- Homogeneity of degree 1 / operation of scalar multiplication


Thus, a linear map is said to be operation preserving. In other words, it does not matter whether the linear map is applied before (the right hand sides of the above examples) or after (the left hand sides of the examples) the operations of addition and scalar multiplication.
By the associativity of the addition operation denoted as +, for any vectors and scalars the following equality holds:[4][5]



Denoting the zero elements of the vector spaces and by and respectively, it follows that Let and in the equation for homogeneity of degree 1:






Occasionally, and can be vector spaces over different fields. It is then necessary to specify which of these ground fields is being used in the definition of "linear". If and are spaces over the same field as above, then we talk about -linear maps. For example, the conjugation of complex numbers is an -linear map , but it is not -linear, where and are symbols representing the sets of real numbers and complex numbers, respectively.



A linear map with viewed as a one-dimensional vector space over itself is called a linear functional.[6]

These statements generalize to any left-module over a ring without modification, and to any right-module upon reversing of the scalar multiplication.


Examples
- A prototypical example that gives linear maps their name is a function , of which the graph is a line through the origin.[7]
- More generally, any homothety where centered in the origin of a vector space is a linear map.
- The zero map between two vector spaces (over the same field) is linear.
- The identity map on any module is a linear operator.
- For real numbers, the map is not linear.
- For real numbers, the map is not linear (but is an affine transformation).
- If is a real matrix, then defines a linear map from to by sending a column vector to the column vector . Conversely, any linear map between finite-dimensional vector spaces can be represented in this manner; see the § Matrices, below.
- If is an isometry between real normed spaces such that then is a linear map. This result is not necessarily true for complex normed space.[8]
- Differentiation defines a linear map from the space of all differentiable functions to the space of all functions. It also defines a linear operator on the space of all smooth functions (a linear operator is a linear endomorphism, that is a linear map where the domain and codomain of it is the same). An example is
- A definite integral over some interval I is a linear map from the space of all real-valued integrable functions on I to . For example,
- An indefinite integral (or antiderivative) with a fixed integration starting point defines a linear map from the space of all real-valued integrable functions on to the space of all real-valued, differentiable functions on . Without a fixed starting point, the antiderivative maps to the quotient space of the differentiable functions by the linear space of constant functions.
- If and are finite-dimensional vector spaces over a field F, of respective dimensions m and n, then the function that maps linear maps to n × m matrices in the way described in § Matrices (below) is a linear map, and even a linear isomorphism.
- The expected value of a random variable (which is in fact a function, and as such a element of a vector space) is linear, as for random variables and we have and , but the variance of a random variable is not linear.
















![{\displaystyle \int _{a}^{b}{\left[c_{1}f_{1}(x)+c_{2}f_{2}(x)+\dots +c_{n}f_{n}(x)\right]dx}={c_{1}\int _{a}^{b}f_{1}(x)\,dx}+{c_{2}\int _{a}^{b}f_{2}(x)\,dx}+\cdots +{c_{n}\int _{a}^{b}f_{n}(x)\,dx}.}](https://www.marefa.org/api/rest_v1/media/math/render/svg/6a1d8d5384ca7abe102f86ba8f6be963fedeb6d2)


![{\displaystyle E[X+Y]=E[X]+E[Y]}](https://www.marefa.org/api/rest_v1/media/math/render/svg/ea2251900ec2b03db1d6f870336155a2a09ff7f1)
![{\displaystyle E[aX]=aE[X]}](https://www.marefa.org/api/rest_v1/media/math/render/svg/3e34453ad80cdf674f4d15fab3e8096be81af79a)
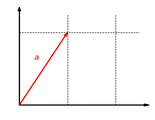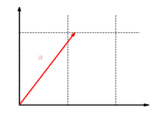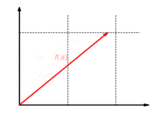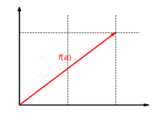
The function with is a linear map. This function scales the component of a vector by the factor .
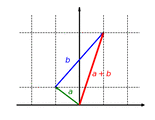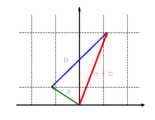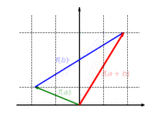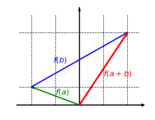
The function is additive: It doesn't matter whether vectors are first added and then mapped or whether they are mapped and finally added:
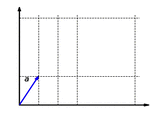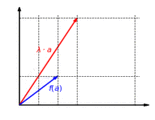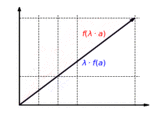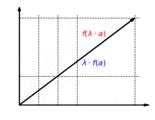
The function is homogeneous: It doesn't matter whether a vector is first scaled and then mapped or first mapped and then scaled:









Matrices
If and are finite-dimensional vector spaces and a basis is defined for each vector space, then every linear map from to can be represented by a matrix.[9] This is useful because it allows concrete calculations. Matrices yield examples of linear maps: if is a real matrix, then describes a linear map (see Euclidean space).


Let be a basis for . Then every vector is uniquely determined by the coefficients in the field :




If is a linear map,

which implies that the function f is entirely determined by the vectors . Now let be a basis for . Then we can represent each vector as




Thus, the function is entirely determined by the values of . If we put these values into an matrix , then we can conveniently use it to compute the vector output of for any vector in . To get , every column of is a vector







The matrices of a linear transformation can be represented visually:
- Matrix for relative to :
- Matrix for relative to :
- Transition matrix from to :
- Transition matrix from to :








Such that starting in the bottom left corner and looking for the bottom right corner , one would left-multiply—that is, . The equivalent method would be the "longer" method going clockwise from the same point such that is left-multiplied with , or .
![{\textstyle \left[\mathbf {v} \right]_{B'}}](https://www.marefa.org/api/rest_v1/media/math/render/svg/38ce4e66d088a57d8adb2aadc461213818bc3220)
![{\textstyle \left[T\left(\mathbf {v} \right)\right]_{B'}}](https://www.marefa.org/api/rest_v1/media/math/render/svg/954ce89644d8b424263ec4dac91becfb6672d931)
![{\textstyle A'\left[\mathbf {v} \right]_{B'}=\left[T\left(\mathbf {v} \right)\right]_{B'}}](https://www.marefa.org/api/rest_v1/media/math/render/svg/d40bbccc105af68b575ef57b62b1e1943c478aaa)

![{\textstyle P^{-1}AP\left[\mathbf {v} \right]_{B'}=\left[T\left(\mathbf {v} \right)\right]_{B'}}](https://www.marefa.org/api/rest_v1/media/math/render/svg/5c713b4830cf922213fe7907677ae35be5fffcfc)
Examples in two dimensions
In two-dimensional space R2 linear maps are described by 2 × 2 matrices. These are some examples:
- rotation
- by 90 degrees counterclockwise:
- by an angle θ counterclockwise:
- by 90 degrees counterclockwise:
- reflection
- through the x axis:
- through the y axis:
- through a line making an angle θ with the origin:
- through the x axis:
- scaling by 2 in all directions:
- horizontal shear mapping:
- squeeze mapping:
- projection onto the y axis:









Vector space of linear maps
The composition of linear maps is linear: if and are linear, then so is their composition . It follows from this that the class of all vector spaces over a given field K, together with K-linear maps as morphisms, forms a category.


The inverse of a linear map, when defined, is again a linear map.
If and are linear, then so is their pointwise sum , which is defined by .




If is linear and is an element of the ground field , then the map , defined by , is also linear.




Thus the set of linear maps from to itself forms a vector space over ,[10] sometimes denoted .[11] Furthermore, in the case that , this vector space, denoted , is an associative algebra under composition of maps, since the composition of two linear maps is again a linear map, and the composition of maps is always associative. This case is discussed in more detail below.






Given again the finite-dimensional case, if bases have been chosen, then the composition of linear maps corresponds to the matrix multiplication, the addition of linear maps corresponds to the matrix addition, and the multiplication of linear maps with scalars corresponds to the multiplication of matrices with scalars.
Endomorphisms and automorphisms
A linear transformation is an endomorphism of ; the set of all such endomorphisms together with addition, composition and scalar multiplication as defined above forms an associative algebra with identity element over the field (and in particular a ring). The multiplicative identity element of this algebra is the identity map .


An endomorphism of that is also an isomorphism is called an automorphism of . The composition of two automorphisms is again an automorphism, and the set of all automorphisms of forms a group, the automorphism group of which is denoted by or . Since the automorphisms are precisely those endomorphisms which possess inverses under composition, is the group of units in the ring .


If has finite dimension , then is isomorphic to the associative algebra of all matrices with entries in . The automorphism group of is isomorphic to the general linear group of all invertible matrices with entries in .



Kernel, image and the rank–nullity theorem
If is linear, we define the kernel and the image or range of by


is a subspace of and is a subspace of . The following dimension formula is known as the rank–nullity theorem:[12]



The number is also called the rank of and written as , or sometimes, ;[13][14] the number is called the nullity of and written as or .[13][14] If and are finite-dimensional, bases have been chosen and is represented by the matrix , then the rank and nullity of are equal to the rank and nullity of the matrix , respectively.






Cokernel
A subtler invariant of a linear transformation is the cokernel, which is defined as

This is the dual notion to the kernel: just as the kernel is a subspace of the domain, the co-kernel is a quotient space of the target. Formally, one has the exact sequence

These can be interpreted thus: given a linear equation f(v) = w to solve,
- the kernel is the space of solutions to the homogeneous equation f(v) = 0, and its dimension is the number of degrees of freedom in the space of solutions, if it is not empty;
- the co-kernel is the space of constraints that the solutions must satisfy, and its dimension is the maximal number of independent constraints.
The dimension of the co-kernel and the dimension of the image (the rank) add up to the dimension of the target space. For finite dimensions, this means that the dimension of the quotient space W/f(V) is the dimension of the target space minus the dimension of the image.
As a simple example, consider the map f: R2 → R2, given by f(x, y) = (0, y). Then for an equation f(x, y) = (a, b) to have a solution, we must have a = 0 (one constraint), and in that case the solution space is (x, b) or equivalently stated, (0, b) + (x, 0), (one degree of freedom). The kernel may be expressed as the subspace (x, 0) < V: the value of x is the freedom in a solution – while the cokernel may be expressed via the map W → R, : given a vector (a, b), the value of a is the obstruction to there being a solution.

An example illustrating the infinite-dimensional case is afforded by the map f: R∞ → R∞, with b1 = 0 and bn + 1 = an for n > 0. Its image consists of all sequences with first element 0, and thus its cokernel consists of the classes of sequences with identical first element. Thus, whereas its kernel has dimension 0 (it maps only the zero sequence to the zero sequence), its co-kernel has dimension 1. Since the domain and the target space are the same, the rank and the dimension of the kernel add up to the same sum as the rank and the dimension of the co-kernel (), but in the infinite-dimensional case it cannot be inferred that the kernel and the co-kernel of an endomorphism have the same dimension (0 ≠ 1). The reverse situation obtains for the map h: R∞ → R∞, with cn = an + 1. Its image is the entire target space, and hence its co-kernel has dimension 0, but since it maps all sequences in which only the first element is non-zero to the zero sequence, its kernel has dimension 1.



Index
For a linear operator with finite-dimensional kernel and co-kernel, one may define index as:

For a transformation between finite-dimensional vector spaces, this is just the difference dim(V) − dim(W), by rank–nullity. This gives an indication of how many solutions or how many constraints one has: if mapping from a larger space to a smaller one, the map may be onto, and thus will have degrees of freedom even without constraints. Conversely, if mapping from a smaller space to a larger one, the map cannot be onto, and thus one will have constraints even without degrees of freedom.
The index of an operator is precisely the Euler characteristic of the 2-term complex 0 → V → W → 0. In operator theory, the index of Fredholm operators is an object of study, with a major result being the Atiyah–Singer index theorem.[15]
Algebraic classifications of linear transformations
No classification of linear maps could be exhaustive. The following incomplete list enumerates some important classifications that do not require any additional structure on the vector space.
Let V and W denote vector spaces over a field F and let T: V → W be a linear map.
- Monomorphism
- T is said to be injective or a monomorphism if any of the following equivalent conditions are true:
- T is one-to-one as a map of sets.
- ker T = {0V}
- dim(ker T) = 0
- T is monic or left-cancellable, which is to say, for any vector space U and any pair of linear maps R: U → V and S: U → V, the equation TR = TS implies R = S.
- T is left-invertible, which is to say there exists a linear map S: W → V such that ST is the identity map on V.
- Epimorphism
- T is said to be surjective or an epimorphism if any of the following equivalent conditions are true:
- T is onto as a map of sets.
- coker T = {0W}
- T is epic or right-cancellable, which is to say, for any vector space U and any pair of linear maps R: W → U and S: W → U, the equation RT = ST implies R = S.
- T is right-invertible, which is to say there exists a linear map S: W → V such that TS is the identity map on W.
- Isomorphism
-
T is said to be an isomorphism if it is both left- and right-invertible. This is equivalent to T being both one-to-one and onto (a bijection of sets) or also to T being both epic and monic, and so being a bimorphism.
If T: V → V is an endomorphism, then:
- If, for some positive integer n, the n-th iterate of T, Tn, is identically zero, then T is said to be nilpotent.
- If T2 = T, then T is said to be idempotent
- If T = kI, where k is some scalar, then T is said to be a scaling transformation or scalar multiplication map; see scalar matrix.
Change of basis
Given a linear map which is an endomorphism whose matrix is A, in the basis B of the space it transforms vector coordinates [u] as [v] = A[u]. As vectors change with the inverse of B (vectors are contravariant) its inverse transformation is [v] = B[v'].
Substituting this in the first expression
![{\displaystyle B\left[v'\right]=AB\left[u'\right]}](https://www.marefa.org/api/rest_v1/media/math/render/svg/c2855717373418c2c2134151c0d0f4d5957292f8)
![{\displaystyle \left[v'\right]=B^{-1}AB\left[u'\right]=A'\left[u'\right].}](https://www.marefa.org/api/rest_v1/media/math/render/svg/65eb8aa4babed0054fcf025303d23fd58309bf7e)
Therefore, the matrix in the new basis is A′ = B−1AB, being B the matrix of the given basis.
Therefore, linear maps are said to be 1-co- 1-contra-variant objects, or type (1, 1) tensors.
Continuity
A linear transformation between topological vector spaces, for example normed spaces, may be continuous. If its domain and codomain are the same, it will then be a continuous linear operator. A linear operator on a normed linear space is continuous if and only if it is bounded, for example, when the domain is finite-dimensional.[16] An infinite-dimensional domain may have discontinuous linear operators.
An example of an unbounded, hence discontinuous, linear transformation is differentiation on the space of smooth functions equipped with the supremum norm (a function with small values can have a derivative with large values, while the derivative of 0 is 0). For a specific example, sin(nx)/n converges to 0, but its derivative cos(nx) does not, so differentiation is not continuous at 0 (and by a variation of this argument, it is not continuous anywhere).
Applications
A specific application of linear maps is for geometric transformations, such as those performed in computer graphics, where the translation, rotation and scaling of 2D or 3D objects is performed by the use of a transformation matrix. Linear mappings also are used as a mechanism for describing change: for example in calculus correspond to derivatives; or in relativity, used as a device to keep track of the local transformations of reference frames.
Another application of these transformations is in compiler optimizations of nested-loop code, and in parallelizing compiler techniques.
انظر أيضاً

- تطبيق ضد خطي
- Bent function
- Bounded operator
- Continuous linear operator
- Linear functional
- التقايس الخطي
Notes
- ^ "Linear transformations of V into V are often called linear operators on V." Rudin 1976
- ^ Let V and W be two real vector spaces. A mapping a from V into W Is called a 'linear mapping' or 'linear transformation' or 'linear operator' [...] from V into W, if
for all ,
for all and all real λ. Bronshtein & Semendyayev 2004 - ^ Rudin 1991
Here are some properties of linear mappings whose proofs are so easy that we omit them; it is assumed that and :- If A is a subspace (or a convex set, or a balanced set) the same is true of
- If B is a subspace (or a convex set, or a balanced set) the same is true of
- In particular, the set: is a subspace of X, called the null space of .
- ^ Rudin 1991. Suppose now that X and Y are vector spaces over the same scalar field. A mapping is said to be linear if for all and all scalars and . Note that one often writes , rather than , when is linear.
- ^ Rudin 1976. A mapping A of a vector space X into a vector space Y is said to be a linear transformation if: for all and all scalars c. Note that one often writes instead of if A is linear.
- ^ Rudin 1991. Linear mappings of X onto its scalar field are called linear functionals.
- ^ "terminology - What does 'linear' mean in Linear Algebra?". Mathematics Stack Exchange. Retrieved 2021-02-17.
- ^ Wilansky 2013, pp. 21-26.
- ^ Rudin 1976
Suppose and are bases of vector spaces X and Y, respectively. Then every determines a set of numbers such that
It is convenient to represent these numbers in a rectangular array of m rows and n columns, called an m by n matrix:Observe that the coordinates of the vector (with respect to the basis ) appear in the jth column of . The vectors are therefore sometimes called the column vectors of . With this terminology, the range of A is spanned by the column vectors of .
- ^ Axler (2015) p. 52, § 3.3
- ^ Tu (2011), p. 19, § 3.1
- ^ Horn & Johnson 2013, 0.2.3 Vector spaces associated with a matrix or linear transformation, p. 6
- ^ أ ب Katznelson & Katznelson (2008) p. 52, § 2.5.1
- ^ أ ب Halmos (1974) p. 90, § 50
- ^ قالب:SpringerEOM: "The main question in index theory is to provide index formulas for classes of Fredholm operators ... Index theory has become a subject on its own only after M. F. Atiyah and I. Singer published their index theorems"
- ^ Rudin 1991
1.18 Theorem Let be a linear functional on a topological vector space X. Assume for some . Then each of the following four properties implies the other three:
- is continuous
- The null space is closed.
- is not dense in X.
- is bounded in some neighbourhood V of 0.

























![{\displaystyle [A]={\begin{bmatrix}a_{1,1}&a_{1,2}&\ldots &a_{1,n}\\a_{2,1}&a_{2,2}&\ldots &a_{2,n}\\\vdots &\vdots &\ddots &\vdots \\a_{m,1}&a_{m,2}&\ldots &a_{m,n}\end{bmatrix}}}](https://www.marefa.org/api/rest_v1/media/math/render/svg/3f53d08efeacd19a7270d82ee81484d772f4e8ef)


![{\textstyle [A]}](https://www.marefa.org/api/rest_v1/media/math/render/svg/efc7c42d7e9f789e2b3384a4f718faddeb0f2119)



ببليوجرافيا
- Axler, Sheldon Jay (2015). Linear Algebra Done Right (3rd ed.). Springer. ISBN 978-3-319-11079-0.
- Bronshtein, I. N.; Semendyayev, K. A. (2004). Handbook of Mathematics (4th ed.). New York: Springer-Verlag. ISBN 3-540-43491-7.
- Halmos, Paul Richard (1974) [1958]. Finite-Dimensional Vector Spaces (2nd ed.). Springer. ISBN 0-387-90093-4.
- Horn, Roger A.; Johnson, Charles R. (2013). Matrix Analysis (Second ed.). Cambridge University Press. ISBN 978-0-521-83940-2.
- Katznelson, Yitzhak; Katznelson, Yonatan R. (2008). A (Terse) Introduction to Linear Algebra. American Mathematical Society. ISBN 978-0-8218-4419-9.
- Lang, Serge (1987), Linear Algebra (Third ed.), New York: Springer-Verlag, ISBN 0-387-96412-6
- قالب:Rudin Walter Functional Analysis
- Rudin, Walter (1976). Principles of Mathematical Analysis. Walter Rudin Student Series in Advanced Mathematics (3rd ed.). New York: McGraw–Hill. ISBN 978-0-07-054235-8.
- قالب:Rudin Walter Functional Analysis
- قالب:Schaefer Wolff Topological Vector Spaces
- قالب:Swartz An Introduction to Functional Analysis
- Tu, Loring W. (2011). An Introduction to Manifolds (2nd ed.). Springer. ISBN 978-0-8218-4419-9.
- قالب:Wilansky Modern Methods in Topological Vector Spaces
